The 5 Biggest Challenges in Managing Microgrid Fleets
Summary: Microgrid fleet management introduces a specific set of operational challenges that aren't a problem for a single-site operation. This article explores the five most common issues fleet operators run into as they scale including fragmented visibility, ineffective remote troubleshooting, cybersecurity exposure, compliance, and coordinated decision-making across distributed sites.
Managing a single microgrid is a limited-scope, single-system responsibility. Operators can monitor performance, diagnose issues, and optimize behavior within a single view of one location.
Managing a fleet of microgrids is different. Operators must maintain visibility across a distributed network of assets spanning multiple remote sites, each with its own mix of systems and operating conditions.
Furthermore, each addition to the fleet further amplifies variation in assets, control systems, and communication architectures, with each deployment introducing its own combination of vendors, control systems, communication protocols, and operating conditions.
At this scale, the challenge is no longer just about visibility at the site level. It becomes about maintaining consistent operational awareness and reliability across a fragmented portfolio of assets operating in different environments, often spread across different geographies and regulatory environments.
The result is a set of recurring operational constraints that most microgrid fleet operators run into as they scale, regardless of technology stack or deployment model.
The sections below outline five of the most common.
1. Fragmented Visibility Across Your Fleet
At an individual site, microgrid operators typically have clear visibility into system performance.
However, as sites are aggregated into a fleet, visibility into asset performance begins to degrade.
Instead of overseeing a unified operational view, operators are faced with a collection of disconnected systems with each representing a single microgrid, that in turn, is composed of assets with their own data structures, interfaces, and operational context.
This means that even basic questions become difficult to answer without manual effort, such as:
Which sites are underperforming relative to others?
Are similar assets behaving consistently across different deployments?
Are emerging issues one-offs, or are they propagating across the fleet?
As a result, operators are forced to navigate between systems, reconcile inconsistent data formats, and mentally construct a view of microgrid fleet health that is not displayed in any single interface.
And as fleets scale, this lack of insight expands.
Consequently, maintaining reliable operations at each site becomes more difficult as operators lose situational awareness, struggle to prioritize interventions, and fail to identify systemic issues before they escalate.

2. The High Cost of Remote Troubleshooting
On-site microgrids allow operators to access local systems, inspect equipment directly, and correlate system behavior with site conditions.
On the other hand, troubleshooting issues at remote microgrid sites is a more convoluted process.
When a fault or performance issue occurs in a distributed microgrid, operators are typically forced to rely on incomplete remote telemetry to understand what is happening and rectify the issue.
However, because each site may have different vendors, control systems, and data configurations, the available information is often inconsistent or partial.
As a result, even basic diagnostic workflows become harder to execute and less reliable:
Different systems must be accessed to reconstruct what happened
Historical data may be stored in separate platforms or formats
Context about recent configuration changes may not be centrally visible
This results in scenarios where operators know that something is wrong but cannot identify the root cause or determine how to resolve it remotely.
In practice, this often leads to dispatching crews to the site to investigate and resolve the issue.
This has direct operational consequences, including:
Increased truck rolls and field service costs
Longer mean time to repair (MTTR)
Delays in resolving issues across multiple sites exhibiting similar symptoms
As fleets grow, this becomes a limiting factor to scaling and a direct risk to site-level uptime.
Each additional site introduces new variations in system behavior, data interfaces, and potential blind spots in remote diagnostics.
The result is a reactive operational model where issues are physically investigated after the fact, rather than being understood and resolved remotely.
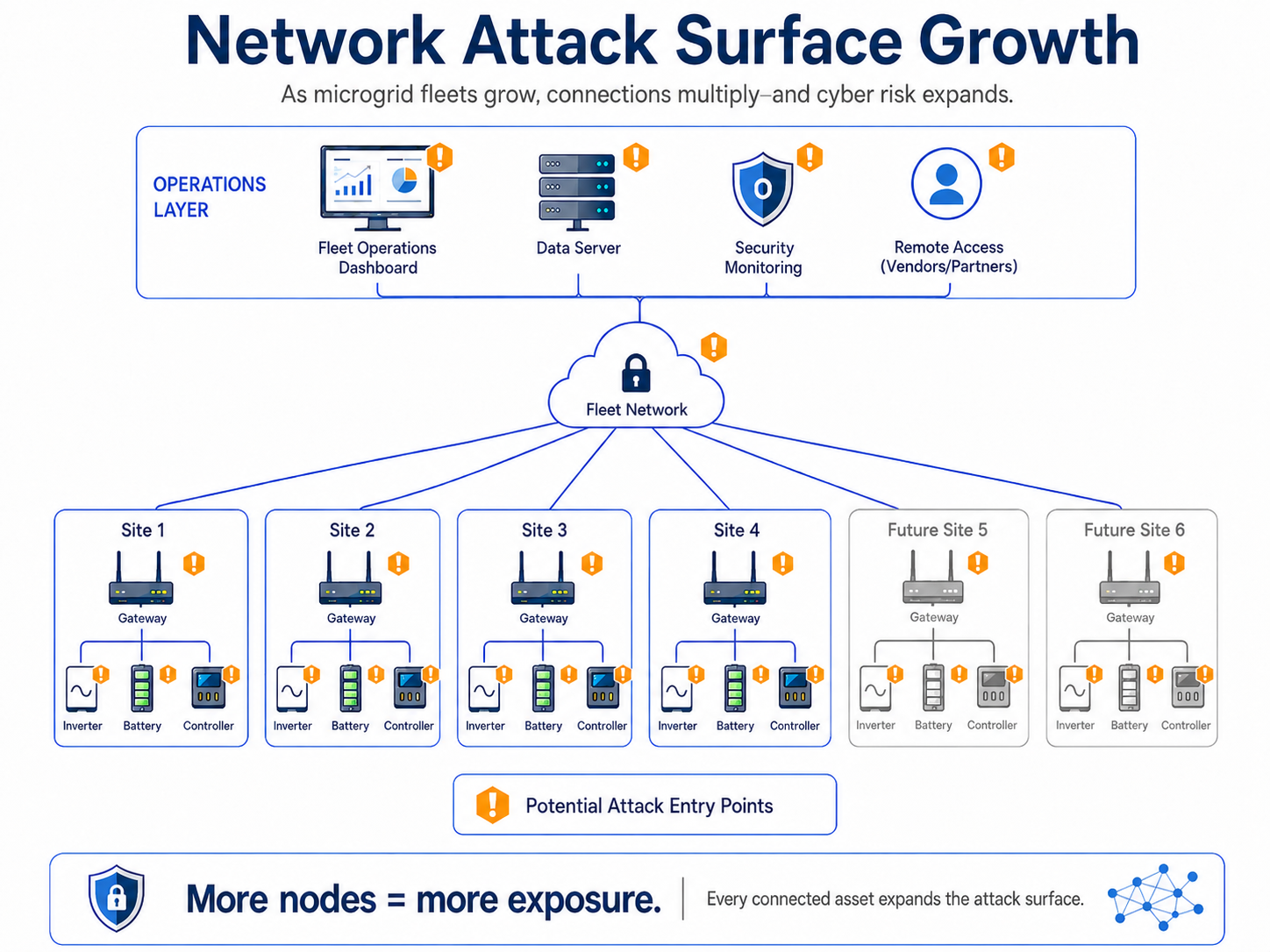
3. Managing an Expanding Cybersecurity Attack Surface When Scaling
As microgrid fleets grow, so does the number of connected assets, control systems, and communication pathways required to operate them. Each new site adds additional nodes (in the form of inverters, batteries, controllers, gateways) to an IIoT network that need to be remotely accessible to enable monitoring and control.
Individually, these connections are necessary for efficient operations.
However, they also represent more entry points on an expanding cybersecurity attack surface that is difficult to fully secure.
Unlike centralized infrastructure, microgrid fleets are inherently distributed.
Systems are deployed across different locations, often with varying network configurations, vendor equipment, and security postures. In many cases, newer digital control layers are introduced into environments that include legacy equipment not originally designed to be networked or secured against modern threats.
This creates several operational challenges, including:
Inconsistent security configurations across sites
Each deployment may follow different standards for authentication, network segmentation, and access control, making it difficult to enforce a unified security model.
Limited visibility into connected assets and access points
Operators may not have a centralized view of all devices, users, and external connections across the fleet, increasing the risk of unmanaged or unknown entry points.
Increased exposure through remote access requirements
Remote monitoring and troubleshooting depend on external connectivity, which, if not tightly controlled, introduces additional risks.
Complex patching and update cycles
Firmware and software updates must be coordinated across diverse hardware and vendor systems, often without centralized control, which can lead to uneven security coverage.
As microgrid fleets grow, these challenges compound. Each additional site introduces new variables, making it harder to maintain consistent security practices while both risk exposure and the potential impact of a breach are escalating.
This leaves the microgrid fleet manager in charge of not just a larger attack surface, but a more difficult one to monitor, secure, and respond to in a coordinated way.
4. Managing NERC CIP Compliance
At a single site, NERC CIP (North American Electric Reliability Corporation Critical Infrastructure Protection) compliance is typically a clearly defined and repeatable process.
Operators understand which systems fall under regulatory scope, what controls must be enforced, and how evidence must be collected for audits. While the process can be time-consuming, it is generally confined to a well-defined scope.
Across a fleet of microgrid deployments, that structure becomes more difficult to keep within familiar bounds.
Each site may have different combinations of assets, control platforms, and vendor configurations deployed at different times. This means that compliance-relevant data is rarely standardized across the fleet and must be manually aggregated for audits.
Consequently, compliance will no longer be a matter of checking that controls exist; it will become a matter of reconstructing whether those controls are consistently applied and documented across every site.
As fleets grow, that burden compounds. Each new site introduces new potential gaps in visibility and documentation, turning NERC CIP compliance from a defined regulatory process into a continuous data management problem.
5. Developing Coordinated Decision-Making Across the Fleet
At a single site, operational decisions are typically straightforward. Issues are identified, addressed, and resolved within a single system and a single operational context.
Across a fleet of nonuniform microgrid deployments, that consistency becomes harder to maintain.
Each site operates with its own combination of equipment, configurations, and control logic. While issues may appear similar across sites, the way they are diagnosed, prioritized, and resolved can vary significantly depending on local conditions and available context.
This is how developing coordinated decision-making becomes a core operational challenge. Because each site operates in its own context, responses are intuitively driven by local knowledge.
Over time, this results in:
Inconsistent responses to similar operational issues
Difficulty prioritizing problems across the fleet
Variation in how changes and fixes are deployed
Reliance on site-specific decision-making rather than centralized direction
The larger the fleet, the more pronounced this inconsistency becomes. The absence of a unified operational dashboard or data layer means that even when visibility and diagnostics exist, execution remains fragmented.
The result is a fleet that is observable, but does not behave as a streamlined operational system.
A Unified Approach to Microgrid Fleet Management
These challenges illustrate a consistent pattern: as microgrid fleets grow, limited visibility and coordination become the primary constraints on operational effectiveness.
Keyfive addresses these challenges directly. Our framework connects assets, control systems, and data sources — including legacy SCADA systems — across every site in your fleet, normalizing data streams into a unified operational view that makes visibility, diagnostics, compliance, and decision-making easy to execute at scale.
If you're running a microgrid fleet and experiencing these challenges, book a demo to see how Keyfive brings unified visibility and coordination to your operation.
Frequently Asked Questions
Why Is It Difficult to Monitor Multiple Microgrid Sites From a Single Interface?
Monitoring multiple microgrid sites from a single interface is challenging because each site is usually configured with its own combination of vendors, hardware, and control systems, and these systems do not produce operational data in a consistent format.
For example, a battery controller and a genset controller from different manufacturers may communicate using entirely different protocols (such as Modbus or DNP3), making it difficult to read and combine their data in a consistent way.
Without a data architecture that can normalize these data streams into a mutually intelligible format, operators will find themselves navigating between disconnected interfaces and manually reconciling inconsistent data in order to compile a less-than-complete picture of fleet health.
Why Do Remote Microgrid Faults Often Require an On-Site Technician to Resolve?
The standard approach for resolving a fault at a remote microgrid site is to analyze the telemetry data to determine what went wrong and the best way to fix it. However, because each site may run different vendors, control systems, and data configurations, that telemetry is often incomplete or inconsistent, which makes it difficult to identify the issue’s root cause without dispatching a technician to the site.
Without normalized data streams feeding into a unified system, this dependency on incomplete remote diagnostics becomes a significant operational constraint as the fleet grows and the number of potential fault sources multiplies.
Why Does NERC CIP Compliance Get More Complex as a Microgrid Fleet Expands?
NERC CIP compliance requires operators to demonstrate that cybersecurity controls are consistently applied across every asset and site within regulatory scope. For a single microgrid site, that scope is well-defined and the evidence collection process straightforward and reproducible.
As a fleet grows, each new site introduces its own combination of assets, control platforms, and vendor configurations, and compliance-relevant data is rarely standardized across deployments. Consequently, maintaining compliance becomes a complicated data management problem and a constant administrative burden.
Keyfive’s reliability framework automates this record keeping in an audit-ready format.